最早是在看dilated convets那篇文章,一直琢磨不懂,为什么predict的时候,作者通过双线性插值上采样过程中要令zoom=8,见下图(在VOC2012数据集上,传参时zoom是8,我试过在其他的数据集,比如cityscape,camvid等上面,zoom=8得到的结果也是效果更好,原因的话,后面就可以明白了):
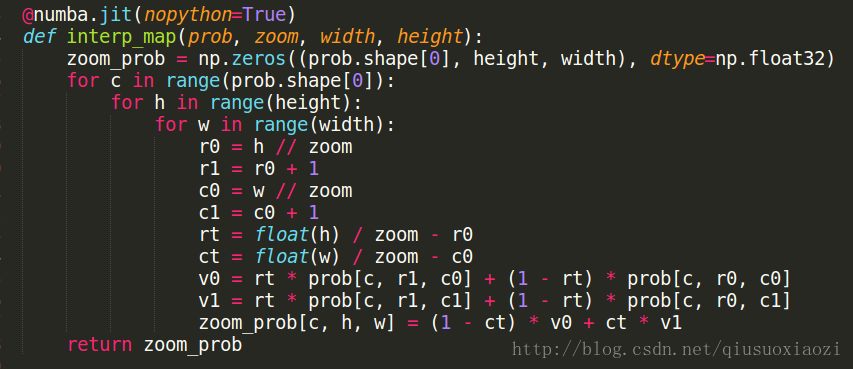
为了搞懂为什么选择8, 我特意给作者发了邮件,遗憾的是,石沉大海。。
直到前两天,在看作者创建的ImageLabelDataLayer的时候,忽然发现了什么。下面是训练的prototxt文件对应的layer
layer {
name: "data"
type: "ImageLabelData"
top: "data"
top: "label"
transform_param {
mirror: true
crop_size: 500
mean_value: 102.930000305
mean_value: 111.36000061
mean_value: 116.519996643
}
image_label_data_param {
image_list_path: "/Databases/VOC07/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007/train_image.txt"
label_list_path: "/Databases/VOC07/VOCtrainval_06-Nov-2007/VOCdevkit/VOC2007/train_label.txt"
batch_size: 7
shuffle: true
label_slice {
dim: 16
dim: 16
stride: 8
stride: 8
offset: 186
offset: 186
}
padding: REFLECT
}
}仔细看上面layer的参数设定,可以发现,图片crop后的大小是500*500,而label_slice设置的参数,使得输出的label只有16*16的大小,再一算,发现500=16*8+186+186这下就水落石出了。也就是说,训练时,神经网络在这种约束下所学习到的label map在原图上也是有stride=8的效果,难怪最后predict的时候要让zoom=8,而这种特性是不依赖于数据集的,所以在不同的数据集上,zoom=8都是最优的!
这么一想,那么offset咋办呢? 神经网络学习到的label,每一个像素抵原图的8个像素,可是原图是500*500,上下左右还是各剩有186宽的像素没有得到学习。 对此,作者的解决办法是:既然每张图都有186的offset没有被predict,那么干脆在预测的时候,不管输入多大的图像,都首先主动的使用REFLECT_101(下面的OpenCV语句)进行186的padding! 这样一来,padding后的图像即便有186的offset得不到预测,那也don’t care了,因为本来就比原图扩大了186。
image = cv2.copyMakeBorder(image, label_margin, label_margin,
label_margin, label_margin,
cv2.BORDER_REFLECT_101)不得不说,这种设计确实很精妙!
除此外,dilated convets的开源代码在使用caffe时也别具特色,非常值得学习。 作者(Fisher Yu)的代码写得很整洁,规范。 而且很新颖地使用python script自动输出训练和预测的prototxt,这一点尤其值得学习,因为caffe的prototxt写起来很麻烦已经饱受诟病了,尤其是对于非常深的网络,如果徒手写很不方便。 我截取了一些Fisher Yu在使用python构造网络并生成prototxt的片段:
def make_frontend_vgg(options, is_training):
batch_size = options.train_batch if is_training else options.test_batch
image_path = options.train_image if is_training else options.test_image
label_path = options.train_label if is_training else options.test_label
net = caffe.NetSpec()
net.data, net.label = network.make_image_label_data(
image_path, label_path, batch_size,
is_training, options.crop_size, options.mean)
last = network.build_frontend_vgg(
net, net.data, options.classes)[0]
if options.up:
net.upsample = network.make_upsample(last, options.classes)
last = net.upsample
net.loss = network.make_softmax_loss(last, net.label)
if not is_training:
net.accuracy = network.make_accuracy(last, net.label)
return net.to_proto()值得注意是,上面片段中的make_image_label_data函数是来自下面。之所以可以有L.ImageLabelData这个python的函数,是因为作者用C++自己定义了ImageLabelDataLayer,然后重新编译了caffe。
def make_image_label_data(image_list_path, label_list_path, batch_size,
mirror, crop_size, mean_pixel,
label_stride=8, margin=186):
label_dim = (crop_size - margin * 2) // 8
data, label = L.ImageLabelData(
transform_param=dict(mirror=mirror, mean_value=mean_pixel,
crop_size=crop_size),
image_label_data_param=dict(
image_list_path=image_list_path, label_list_path=label_list_path,
shuffle=True, batch_size=batch_size,
padding=P.ImageLabelData.REFLECT,
label_slice=dict(dim=[label_dim, label_dim],
stride=[label_stride, label_stride],
offset=[margin, margin])),
ntop=2)
return data, label最后网络生成完后,打开文本文件,直接写进去:
with open(options.train_net, 'w') as fp:
fp.write(str(train_net))
if test_net is not None:
print('Writing', options.test_net)
with open(options.test_net, 'w') as fp:
fp.write(str(test_net))
print('Writing', options.solver_path)
with open(options.solver_path, 'w') as fp:
fp.write(str(solver))以上可以Fisher Yu在使用C++写layer,以及用pycaffe,python生成prototxt方面很擅长,这些技能一定要学会,以后我也可以这么做!
这篇博客本来是要专注讲zoom value的一些杂碎的,所以回到主题。
另一个与Fisher Yu细致的训练和预测思路不同的一个例子,就是大名鼎鼎的FCN了。
FCN在这方面相对比较“粗暴”。
大体上来说,FCN在训练的时候充分考虑了不同的图片的各异性,让各图片自由发挥,不像dilated convets那样统一crop成500*500的大小,这样一来,期望的label map就大小各异了,因此在输出的时候,先将经过卷积层下采样后的feature map上采样到比原图大(或等于原图大小),然后用输入层的label作为bottom,crop到和原图一样大小就OK了。 另外,由于没有统一输入data的大小,害怕下采样的过程有的小图片经不起“这份折磨”(怕下采样采没了),所以作者在第一层卷积层就大刀阔斧来了一个100的padding,这样势必带来很多噪声,也是我觉得FCN比较粗暴的主要原因。而在预测的时候,作者在infer.py文件中,根据被预测图片的大小动态的改变data layer blob的shape,使之能够适应各种形状大小图片的输入。
需要提到的是,作为DL在语义分割领域的排头兵,FCN自然少不了摒弃caffe自带的专为classification而生的ImageDataLayer,而构造自己的data layer(见下面prototxt中的SBDDSegDataLayer)。 FCN独出心裁地使用了python layer来创建自己的data layer(这刚好和dilated convnets不同,因为Fisher Yu是使用C++写的data layer,然后编译的),从敏捷开发的角度,FCN使用python layer的方法也非常值得学习! FCN在使用python layer方面确实玩得非常6,而且另一方面由于data layer不需要GPU加速,所以使用python layer的方法也是不损失性能的。
layer {
name: "data"
type: "Python"
top: "data"
top: "label"
python_param {
module: "voc_layers"
layer: "SBDDSegDataLayer"
param_str: "{\'sbdd_dir\': \'../data/sbdd/dataset\', \'seed\': 1337, \'split\': \'train\', \'mean\': (104.00699, 116.66877, 122.67892)}"
}
}FCN在预测的时候,Input的shape约定在500*500
layer {
name: "input"
type: "Input"
top: "data"
input_param {
# These dimensions are purely for sake of example;
# see infer.py for how to reshape the net to the given input size.
shape { dim: 1 dim: 3 dim: 500 dim: 500 }
}
}但是在实际infer的时候,又在pycaffe中随心所欲地改起了data的shape,见下面的代码片段(来自infer.py),倒数第二行就是适应地把data的shape改成和in_的大小一样,然后最后一行才可以把in_喂进网络。
im = Image.open('images/dog.jpg')
# im = Image.open('images/hello.png')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
# It seems the following two lines make the data blob of the net change the shape dynamically with the data being feeded
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_这么不断地改data blob的shape,从而能接收到原汁原味的原图,这也是和FCN的训练过程是一致的,因为FCN的训练也是喂进去原汁原味的图片。 所以可以看到,不管是dilated covnets还是FCN,predict和train总是要契合的!
总结:
上面讲到了dilated covnets和FCN在面对语义分割(或者广义的dense prediction问题时)各具特色的train,predict的处理思路。
另外还有值得学习的就是:
- dilated convnets: C++写layer,编译caffe后使用pycaffe,python自动生成prototxt的方法
- FCN: 使用python layer写data layer,在python中动态更改data blob shape的方法(这种“耍流氓”的方法确实不错,不然我也想不到还有什么办法喂给神经网络原汁原味大小的图片了,毕竟deploy.prototxt中Input layer大小是预先指定的)
最后。。写完后,发现写的内容和题目相关性好像不太紧密,不过也想不到别的题目了,所以。。。
完!


