sam是2023年提出的一个在图像分割领域的大模型,其具备了对任意现实数据的分割能力,其论文的介绍可以参考 https://hpg123.blog.csdn.net/article/details/131137939,sam的亮点在于提出一种工作模式,同时将多形式的prompt集成到了语义分割中,其网络结构并没有特殊设计。拓展sam所发展的mobile-sam只是对sam项目中图像编码器的优化,并未在技术提出显著的亮点。故而对sam工作模式进行深入分析,主要深入分析sam的模型设计范式、数据标签范式、fast-sam模型训练范式。
sam的试用地址为:https://segment-anything.com/demo
本博文主要参考资料来自:https://hpg123.blog.csdn.net/article/details/131137939、https://hpg123.blog.csdn.net/article/details/131234476、https://hpg123.blog.csdn.net/article/details/131194434
通过本博文的查阅与分析,实现fastsam是较为简便的,且fastsam的性能可以随着全景实例分割模型的发展而进一步提升,同时也说明了fastsam中prompt的实现。而在sam中,各种实现较为生涩难懂,主要说明sam的模型结构,基本原理,数据生成范式。sam的亮点在于基于少量的语义分割标签,迭代出了一个1.1B 标签超大型数据集,其不断扩展标注数据量的思想是值得学习的;而在fastsam中则是对SAT重新定义得出SAT,基于对全景实例分割模型的后处理实现了类似sam的性能。从sam到fastsam所透露的是数据伪标签拓展的重要性,没有sam发布的数据集,fastsam是无法达到预期性能的。
1、模型设计范式
1.1 sam范式分析
根据论文给出的图表来看,sam的输入包含2部分,原始图片与Prompt(mask、point、boxes、text其中text是基于clip进行编码直接输入)。
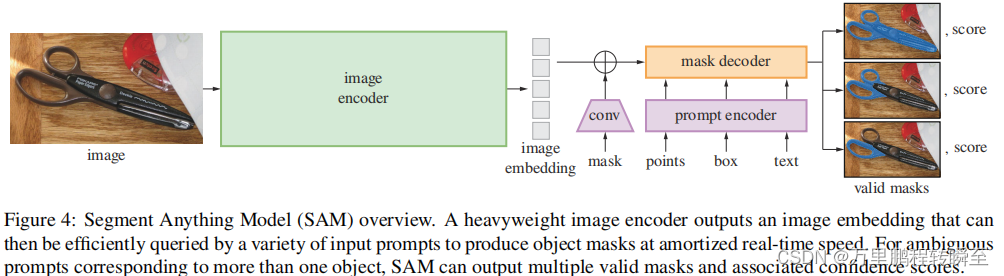
从sam发布的代码来看,其prompt仅包含mask、point、boxes,且三者处于等价地位(同时其官网也未提供基于text的解码)。由代码所得出的sam模型体系如下所示,具体为3个步骤:1.图像编码、2.promp编码、3. 根据promp编码对图像进行解码操作。在mobilenet中完全延用了sam的范式,只是对image_encoder进行了一个蒸馏,从而实现了性能的提升 ; 在fast-sam中只是正式提出将SAT分解为2阶段,第一阶段为对输入图像的全景实例分割,第二阶段为根据提示输入对全景实例分割结果进行稀疏化选择

在mobilesam论文给出的sam结构图中,可以看出sam模型的主要参数在图像编码器中,而在prompt部分较少
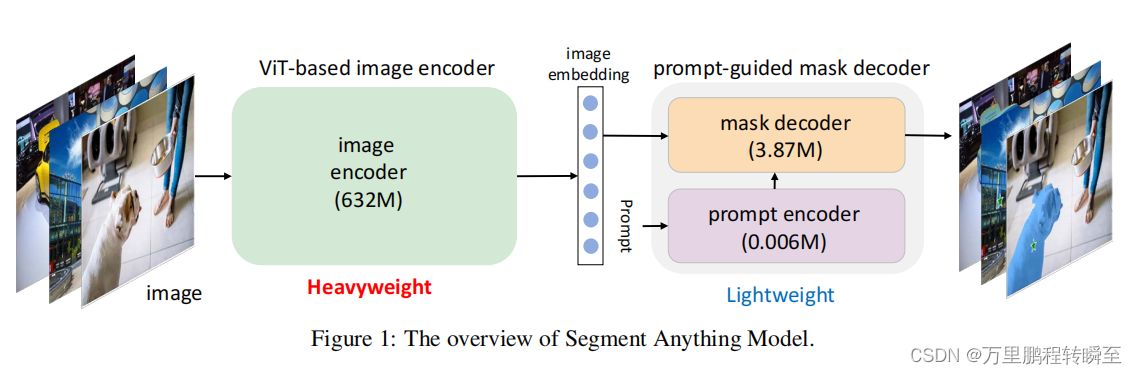
1.2 图像编码器简介
在sam中使用ImageEncoderViT作为图像编码器,其性能饱和慢随着数据增长,精度可持续增长,用到了1100万的训练图片。原始ViT也是在 ImageNet、ImageNet-21k和JFT- 300M进行训练,并表明JFT-300M效果更好。sam中的Vit与原始模型有细微差异,其输入shape为3x1024x1024,输出的feature map为256x64x64。 这里可以透露出sam最多分割256个mask,这样子设计或许与mask图像uint8的表示范围有关
补偿知识:
1、mobile-sam使用解耦蒸馏方法(只对图像编码器进行蒸馏),使backbone与原始的解码器相适应,整个训练在一个GPU上不到一天,将编码器参数减少100倍,总参数减少60倍。
2、mobile-sam蒸馏后的图像编码器运行为8 ms,mask解码器运行为2 ms,总体运行时间为10ms,比FastSAM快4倍。
3、mobile-sam其基于conv和transformer设计了轻量化的图像编码器;同时,为了加快训练,保存了教师模型预测的特征编码,减少了知识蒸馏中教师模型forward的时间。
1.3 PromptEncoder简介
PromptEncoder属于轻量化的结构,用于对输入模型的points、boxes和masks信息进行编码,将其统一为空间特征编码的格式。其对points、boxes和masks编码时允许有部分值空缺(空缺使用默认值),其将points和boxes组装为sparse_embeddings,将mask组装为dense_embeddings 其对mask的采样由多个attention层实现,具体可见mask_downscaling函数。
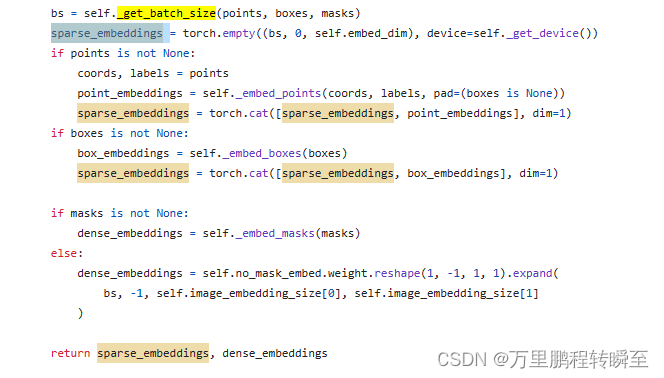
PromptEncoder将points、boxes编码为sparse_embeddings拼接在一起,将mask编码为dense_embeddings;同时允许任意prompt输入为空
1.4 MaskDecoder说明
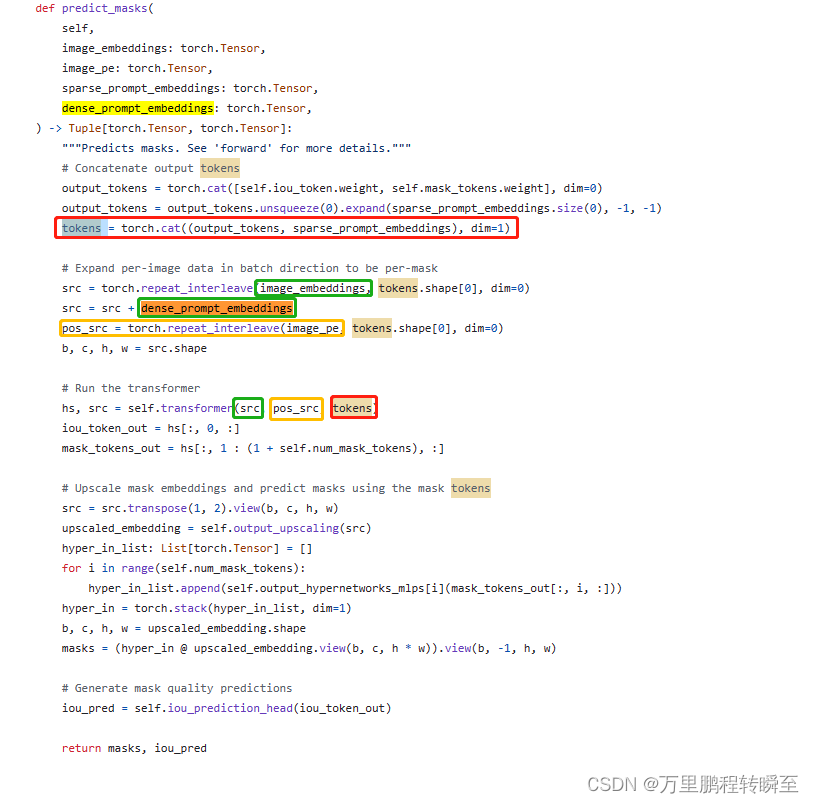
MaskDecoder是sam的核心部分,用于根据输入给出预期输出。其核心代码为predict_masks函数,输入包含
image_embeddings、image_pe、sparse_prompt_embeddings、dense_prompt_embeddings,
在这个过程中代表mask的dense_prompt_embeddings与image_embeddings直接作用,对应的输出经过TwoWayTransformer后变为了mask_tokens_out
代表box与point的sparse_prompt_embeddings与iou_token直接作用,对应的输出经过TwoWayTransformer后变为了iou_token_out .
最后由IOU预测模块,输出每个mask的iou
MaskDecoder的本质就是根据图像编码与prompt编码输出mask与iou得分(基于输出的mask、iou得分,或许可以与标签mask、标签iou得分进行训练),至于为什么计较这么复杂,博主尚未理清楚。或许参考fast-sam的实现可以理通,但从mobile的实现思路来看是可以规避这个问题(直接使用sam的MaskDecoder)。
2、数据标签范式
2.1 Segment Anything Dataset
sam提出了数据集Segment Anything Dataset,其中包含由1100万多样化、高分辨率、许可和隐私保护图像(平均像素3300×4950),并包含1.1B高质量分割掩码(其中99.1%是完全自动生成的;并抽取了500个图【50k个mask】进行了人工验证,94%的图像对IoU大于90%(97%的对的IoU大于75%))。
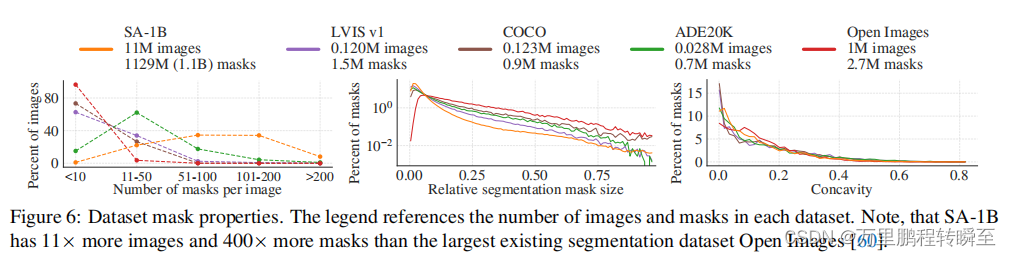
sad的数据分布特性如下所示,大部分数据的mask数量处于50~200个。
sad的地址:https://segment-anything.com/dataset/index.html
其数据实例如下所示,并没有形成一个完整的全景实例分割数据集,部分数据仅对较显眼部分(前景)进行标注,对背景标注较少(如,地面和输,标注就比较少)。

2.2 SAD数据引擎
Segment Anything Data Engine分为三个阶段: (1)模型辅助手动标注阶段,(2)包含自动预测掩码和模型辅助标注的半自动阶段,(3)全自动阶段,在此阶段中,我们的模型生成掩码而无需标注器输入;最终生成Segment Anything Dataset。
辅助手动阶段:类似于经典的交互式分割,通过点击前景/背景对象点来标记掩码,要求按突出程度的顺序标记物体,自动生成mask。mask可以使用像素精确的“笔刷”和“橡皮擦”工具来改进。
同时,SAM使用常见的公共分割数据集进行训练。在进行足够的数据标注后,只使用新标注的掩码进行重新训练。随着更多的掩模被收集到,图像编码器从ViT-B缩放到ViT-H,同时训练细节随着模型调整不断优化。总共对模型进行了6次再训练。随着模型的改进,每个mask的平均标注时间从34秒减少到14秒; 每幅图像的平均掩模数量从20个增加到44个; 从12万张图像中收集了430万个mask
该阶段,要求已经具备类似sam的模型能根据prompt进行初级的语义分割能力,只是类sam模型预测的结果有待人工优化。
半自动阶段: 在这个阶段,目标是增加mask的多样性,以提高模型分割任何东西的能力。为了将标注器集中在不太突出的对象上,首先自动检测到较为突出的mask。然后,我们提供了预先填充了这些掩码的图像的标注器,并要求它们标注任何其他未标注的对象。
为了检测突出的掩模,将第一阶段所有的mask都整理成目标检测标签,类别为“object”,训练了一个边界框检测器[84]。然后要求检测器自动检测出突出的mask的boxes,然后根据boxes重新进行mask生成在这一阶段,在18万张图像中收集了额外5.9M的mask(总共有10.2M的mask)
与第一阶段一样,定期使用新收集的数据重新训练模型(5次),该操作使mask数量从44个增加到72个(包括自动mask)
该阶段,主要目的就是泛化检测模型对突出物体的检测能力,找到未标注区域、泛化sam对未标注区域的标签生成能力。先基于检测模型找到待标注的显著区域,然后使用模型生成伪标签,不断扩展数据的mask数量,同时相比于第一阶段,补充了6万个数据
全自动阶段:
该阶段有两个主要的增强,1:mask足够充分,2、设计了模糊感知模型,它允许在模糊情况下预测出有效mask。
该阶段已经使用了sam的自动分割功能,用一个32×32规则点网格提示模型,为每个点预测一组可能对应于有效对象的掩模上一个阶段使用检测模型进行标注。如果点位于一个部分或子部分上,模糊感知模型将返回该子部分、部件和整个对象。模型的IoU预测模块用于选择自信的掩模;此外,只识别和选择稳定的mask。最后,在选择了自信和稳定的掩模后,应用非最大抑制(NMS)来过滤多余mask。
trick1:为了进一步提高较小掩模的质量,处理了多个重叠的放大图像crop。有关此阶段的详细信息
对数据集中的所有11M幅图像应用了全自动掩模生成,总共产生了1.1B个高质量的掩模。
3、fast-sam模型训练范式
sam只是对Segment Anything进行了一个初步的定义,描述了其是如何基于0.9%的人工数据标签生成100%的数据,并未讲述其对sad数据集的再训练。
fast-sam项目地址为:https://github.com/CASIA-IVA-Lab/FastSAM
fast-sam demo地址为:https://huggingface.co/spaces/An-619/FastSAM
3.1 Segment Anything Task定义
FastSAM定义Segment Anything Task(SAT)为根据提示进行语义分割任务,提示指:前景|背景点、bounding boxes、mask、text;
FastSAM将SAT分解为2阶段,第一阶段为对输入图像的全景实例分割,第二阶段为根据提示输入对全景实例分割结果进行稀疏化选择。其能如此实现,主要是sad完成了数据mask从稀疏到全景的标注
3.2 fast-sam实现
fast-sam由yolov8-seg(全景实例分割)+Prompt-guided-Selection模块组成,从其结构图中可以看到两个模块是可以孤立训练的。
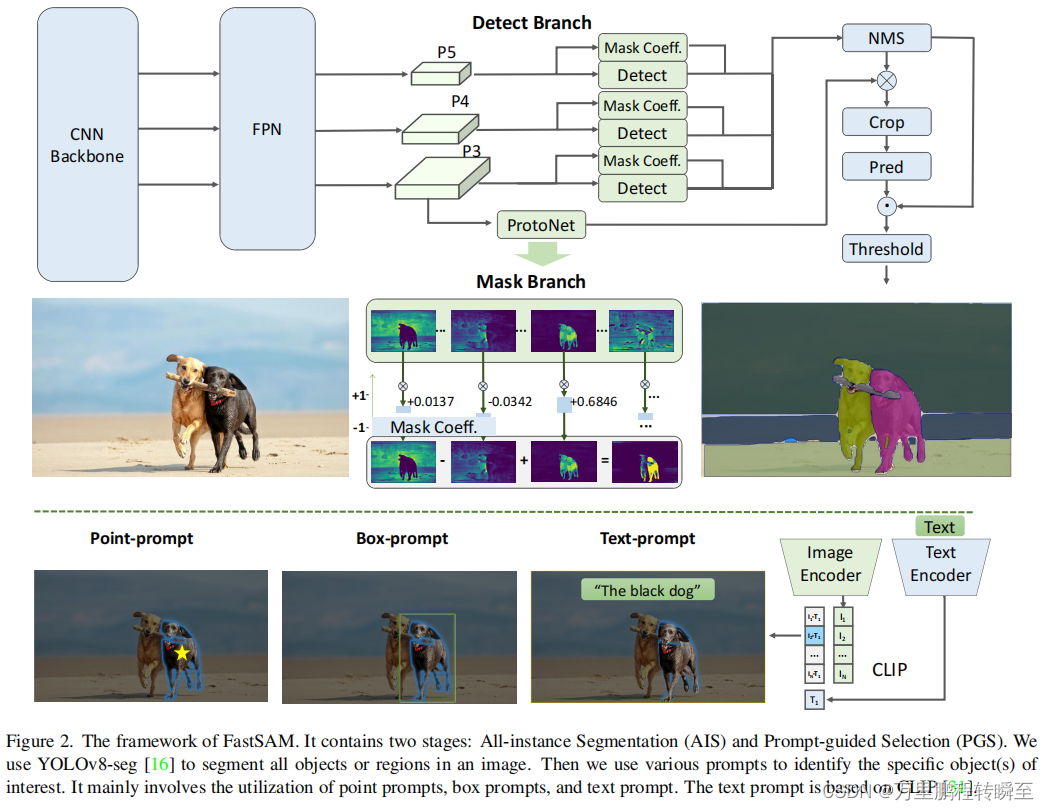
这里以ultralytics中对fast-sam的实现为基准,可以看到FastSAM就是对yolov8模型的继承,这里的FastSAM只是一个通用的全景实例分割模型。
# Ultralytics YOLO 🚀, AGPL-3.0 license
from pathlib import Path
from ultralytics.engine.model import Model
from .predict import FastSAMPredictor
from .val import FastSAMValidator
class FastSAM(Model):
"""
FastSAM model interface.
Example:
```python
from ultralytics import FastSAM
model = FastSAM('last.pt')
results = model.predict('ultralytics/assets/bus.jpg')
```
"""
def __init__(self, model='FastSAM-x.pt'):
"""Call the __init__ method of the parent class (YOLO) with the updated default model."""
if str(model) == 'FastSAM.pt':
model = 'FastSAM-x.pt'
assert Path(model).suffix not in ('.yaml', '.yml'), 'FastSAM models only support pre-trained models.'
super().__init__(model=model, task='segment')
@property
def task_map(self):
"""Returns a dictionary mapping segment task to corresponding predictor and validator classes."""
return {'segment': {'predictor': FastSAMPredictor, 'validator': FastSAMValidator}}
其使用代码如下所示,先由FastSAM分割出全景mask,再由FastSAMPrompt根据输入提示筛选mask
from fastsam import FastSAM, FastSAMPrompt
import torch
model = FastSAM('FastSAM.pt')
IMAGE_PATH = './images/dogs.jpg'
DEVICE = torch.device(
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
everything_results = model(
IMAGE_PATH,
device=DEVICE,
retina_masks=True,
imgsz=1024,
conf=0.4,
iou=0.9,
)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# # everything prompt
ann = prompt_process.everything_prompt() #这里就是everything_results
# # bbox prompt
# # bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
# bboxes default shape [[0,0,0,0]] -> [[x1,y1,x2,y2]]
# ann = prompt_process.box_prompt(bbox=[200, 200, 300, 300])
# ann = prompt_process.box_prompt(bboxes=[[200, 200, 300, 300], [500, 500, 600, 600]])
# # text prompt
# ann = prompt_process.text_prompt(text='a photo of a dog')
# # point prompt
# # points default [[0,0]] [[x1,y1],[x2,y2]]
# # point_label default [0] [1,0] 0:background, 1:foreground
# ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(
annotations=ann,
output='./output/',
mask_random_color=True,
better_quality=True,
retina=False,
withContours=True,
)
3.3 FastSAMPrompt
FastSAMPrompt是fastsam的核心,其用于根据prompt从现有全景分割结果中遴选出目标mask。其本身不带任何可训练参数,从代码上看其仅支持point、box、text形式的prompt不支持mask嵌入。
bbox prompt
实现代码如下所示,代码行数较多,以博主的理解就是根据bbox 生成mask,然后计算与全景分割所有mask的iou,然后找出iou最大的进行输出。因此,这里输入bbox ,只会输出一个mask。
def box_prompt(self, bbox):
"""Modifies the bounding box properties and calculates IoU between masks and bounding box."""
if self.results[0].masks is not None:
assert (bbox[2] != 0 and bbox[3] != 0)
if os.path.isdir(self.source):
raise ValueError(f"'{self.source}' is a directory, not a valid source for this function.")
masks = self.results[0].masks.data
target_height, target_width = self.results[0].orig_shape
h = masks.shape[1]
w = masks.shape[2]
if h != target_height or w != target_width:
bbox = [
int(bbox[0] * w / target_width),
int(bbox[1] * h / target_height),
int(bbox[2] * w / target_width),
int(bbox[3] * h / target_height), ]
bbox[0] = max(round(bbox[0]), 0)
bbox[1] = max(round(bbox[1]), 0)
bbox[2] = min(round(bbox[2]), w)
bbox[3] = min(round(bbox[3]), h)
# IoUs = torch.zeros(len(masks), dtype=torch.float32)
bbox_area = (bbox[3] - bbox[1]) * (bbox[2] - bbox[0])
masks_area = torch.sum(masks[:, bbox[1]:bbox[3], bbox[0]:bbox[2]], dim=(1, 2))
orig_masks_area = torch.sum(masks, dim=(1, 2))
union = bbox_area + orig_masks_area - masks_area
iou = masks_area / union
max_iou_index = torch.argmax(iou)
self.results[0].masks.data = torch.tensor(np.array([masks[max_iou_index].cpu().numpy()]))
return self.results
point prompt
point 的实现代码如下所示,其本质就是遍历所有全景分割mask,将point正例所击中的mask添加到onemask 中,将point负例所击中的mask从onemask 中删除,然后返回onemask
def point_prompt(self, points, pointlabel): # numpy
"""Adjusts points on detected masks based on user input and returns the modified results."""
if self.results[0].masks is not None:
if os.path.isdir(self.source):
raise ValueError(f"'{self.source}' is a directory, not a valid source for this function.")
masks = self._format_results(self.results[0], 0)
target_height, target_width = self.results[0].orig_shape
h = masks[0]['segmentation'].shape[0]
w = masks[0]['segmentation'].shape[1]
if h != target_height or w != target_width:
points = [[int(point[0] * w / target_width), int(point[1] * h / target_height)] for point in points]
onemask = np.zeros((h, w))
for annotation in masks:
mask = annotation['segmentation'] if isinstance(annotation, dict) else annotation
for i, point in enumerate(points):
if mask[point[1], point[0]] == 1 and pointlabel[i] == 1:
onemask += mask
if mask[point[1], point[0]] == 1 and pointlabel[i] == 0:
onemask -= mask
onemask = onemask >= 1
self.results[0].masks.data = torch.tensor(np.array([onemask]))
return self.results
text prompt
相关代码如下所示,关键函数为retrieve。其先使用_crop_image将全景实例分割中mask对应的图片全部crop出来,然后使用clip分别计算出mask crop与tokenized_text 的余弦相似度,最后找出余弦相似度大于阈值的mask即可。
def text_prompt(self, text):
"""Processes a text prompt, applies it to existing results and returns the updated results."""
if self.results[0].masks is not None:
format_results = self._format_results(self.results[0], 0)
cropped_boxes, cropped_images, not_crop, filter_id, annotations = self._crop_image(format_results)
clip_model, preprocess = self.clip.load('ViT-B/32', device=self.device)
scores = self.retrieve(clip_model, preprocess, cropped_boxes, text, device=self.device)
max_idx = scores.argsort()
max_idx = max_idx[-1]
max_idx += sum(np.array(filter_id) <= int(max_idx))
self.results[0].masks.data = torch.tensor(np.array([annotations[max_idx]['segmentation']]))
return self.results
@torch.no_grad()
def retrieve(self, model, preprocess, elements, search_text: str, device) -> int:
"""Processes images and text with a model, calculates similarity, and returns softmax score."""
preprocessed_images = [preprocess(image).to(device) for image in elements]
tokenized_text = self.clip.tokenize([search_text]).to(device)
stacked_images = torch.stack(preprocessed_images)
image_features = model.encode_image(stacked_images)
text_features = model.encode_text(tokenized_text)
image_features /= image_features.norm(dim=-1, keepdim=True) #先除模
text_features /= text_features.norm(dim=-1, keepdim=True) #先除模
probs = 100.0 * image_features @ text_features.T #再做乘法,实现余弦相似度计算
return probs[:, 0].softmax(dim=0)
def _crop_image(self, format_results):
"""Crops an image based on provided annotation format and returns cropped images and related data."""
if os.path.isdir(self.source):
raise ValueError(f"'{self.source}' is a directory, not a valid source for this function.")
image = Image.fromarray(cv2.cvtColor(self.results[0].orig_img, cv2.COLOR_BGR2RGB))
ori_w, ori_h = image.size
annotations = format_results
mask_h, mask_w = annotations[0]['segmentation'].shape
if ori_w != mask_w or ori_h != mask_h:
image = image.resize((mask_w, mask_h))
cropped_boxes = []
cropped_images = []
not_crop = []
filter_id = []
for _, mask in enumerate(annotations):
if np.sum(mask['segmentation']) <= 100:
filter_id.append(_)
continue
bbox = self._get_bbox_from_mask(mask['segmentation']) # mask 的 bbox
cropped_boxes.append(self._segment_image(image, bbox)) # 保存裁剪的图片
cropped_images.append(bbox) # 保存裁剪的图片的bbox
return cropped_boxes, cropped_images, not_crop, filter_id, annotations