🍁🍁🍁图像分割实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
1、空洞卷积
图像分割中的传统做法:为了增大感受野,通常都会选择pooling操作,但是也会丢失一部分信息
当需要检测、分割的目标比较小的时候,这些小目标在图像中的占据的位置也比较小,只需要局部的特征就可以识别,那些目标比较大、还有识别难度比较大的目标,只用局部的特征就不好做这个物体的识别。
这个应该怎么做呢?一般在深度学习中,需要堆叠很多很多层,目的就是通过各种各样的卷积和偏执权重参数去拟合数据,还有就是扩充一个东西,就是感受野。经过多次卷积,特征图的一个点,可能会代表原始图像中一个比较大的区域,一个点所能代表的区域大小,就是感受野。所以目标大、难度的物体,包含的特征比较多,所以需要多次卷积至特征图比较小的时候,得到高阶特别才能比较好的识别这个物体。
一般的做法就是,每隔两次卷积,做一次pooling,并且重复这个堆叠,堆叠的越多感受野肯定越大。但是在感受野增大的过程中,也会丢失一些信息,这里的问题出在哪儿呢?就是做pooling的时候丢失了信息。
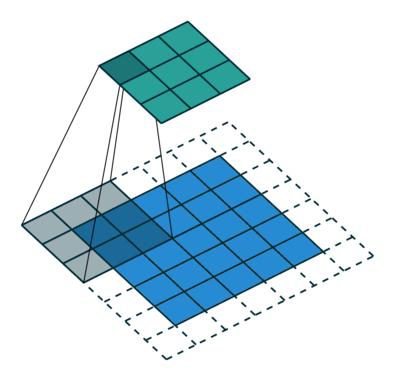
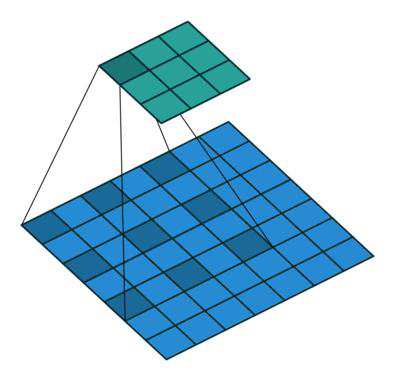
传统卷积,加上padding的原因是因为边缘信息被计算的比较少,空洞卷积解决这个问题的方法是卷积个数没变,但是卷积区域变化了,每次卷积过程中,只有部分数据参与计算,这样的计算方式比传统卷积的特征的感受野变大了一些。
通过设置dilated参数可以得到不同感受野的特征(3 * 3,7 * 7,15 * 15)
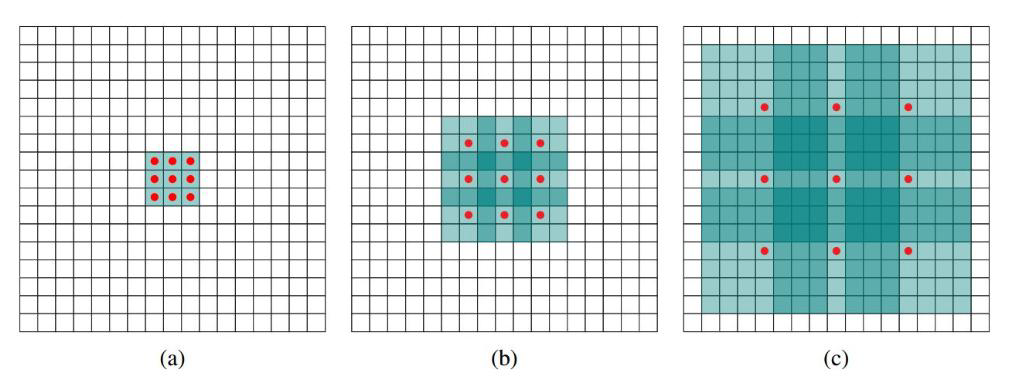
2、空洞卷积的优势
- 图像分割任务中(其他场景也适用)需要较大感受野来更好完成任务
- 通过设置dilation rate参数来完成空洞卷积,并没有额外计算
- 可以按照参数扩大任意倍数的感受野,而且没有引入额外的参数
- 应用简单,就是卷积层中多设置一个参数就可以了
3、感受野
deeplab这个网络总是在强调感受野这个概念
如果堆叠3个3x3的卷积层,并且保持滑动窗口步长为1,其感受野就是77的了,这跟一个使用77卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
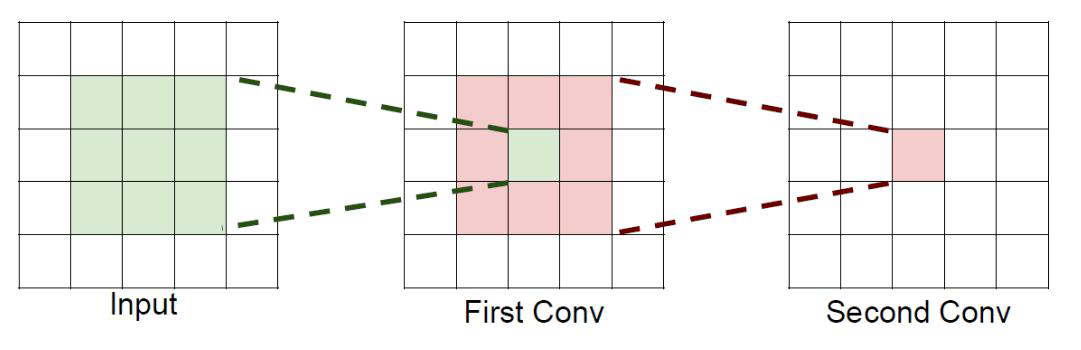
假设输入大小都是h* w *c,并且都使用c个卷积核(得到c个特征图),可以来计算一下其各自所需参数:
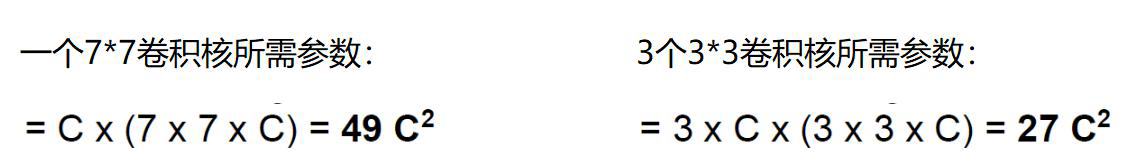
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,因为每次卷积后都会经过激活函数和BatchNormalization,还不会增大权重参数个数,这就是VGG网络的基本出发点,用小的卷积核来完成体特征提取操作
4、SPP-Layer
SPP层,spatial pyramid pooling layer
- 网络中通常要求输入固定
- SPP通用不同的池化层
- 再进特征拼接
- 只要保障输入特征固定就可以了
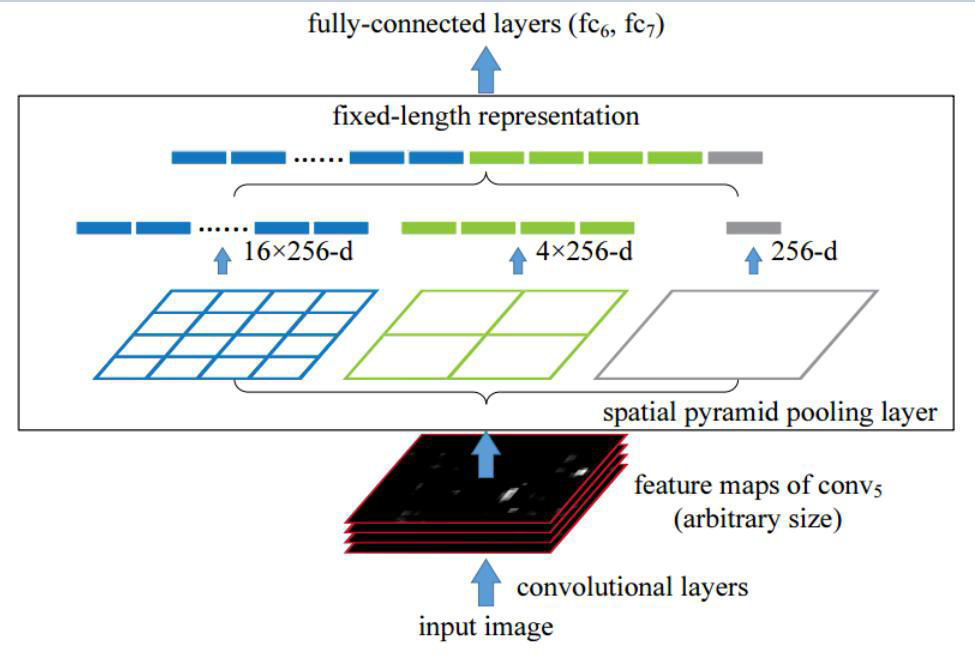
在图像处理中,有图像金字塔这个概念,就是将一个图像调整多个分辨率,对应出多个图像就是图像金字塔。对应到网络中,实际的输入大小是不确定的,如果能让网络自己能够适应,但是被全连接层限制住了,因为最后输出的分类个数是确定的。
SPP层就是将特征图分成3种,假设特征图是n * n,将其分别分为a * a、b * b、c * c个格子,其中a>b>c,然后每个格子都通过Maxpooling,最后得到a * a、b * b、c * c个特征值,再将其拼接起来,但是在这里是不涉及到特征图的个数的,所以还会乘上特征图的个数。这个过程如上图所示。
4.1 常用的多尺度特征提取方法:
这些方法都比较通用,在各项视觉任务中均可以使用
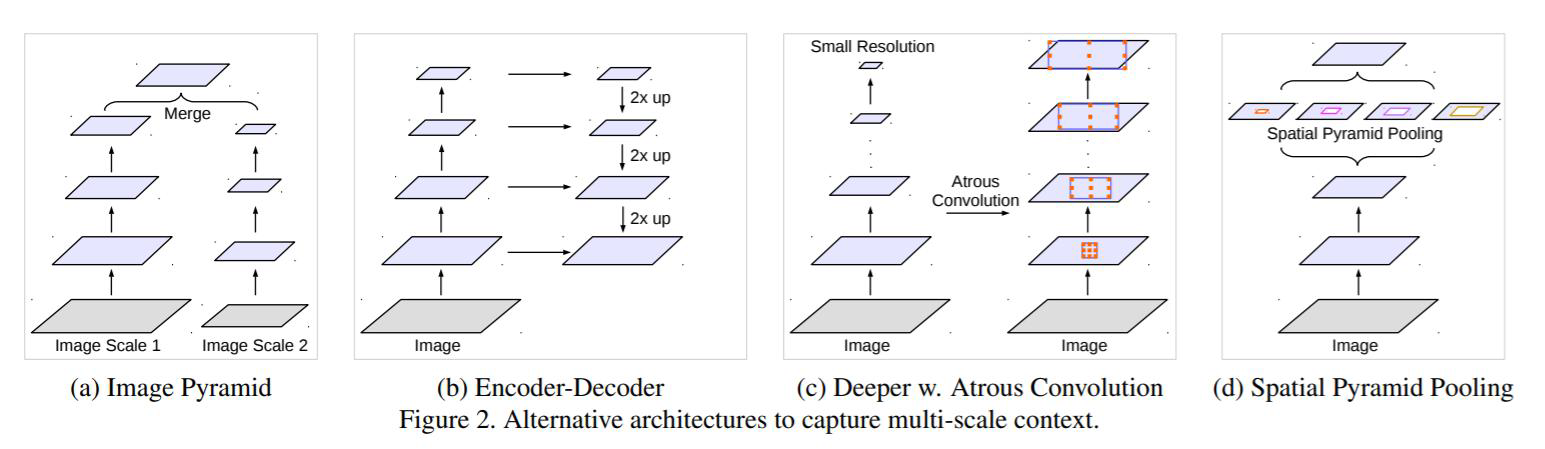
(a) 传统的图像金字塔方法,将不同尺度的图像经过多层卷积后做特征拼接
(b) 第二种就是Unet方法
© 第三张就是空洞卷积
(d) 第四种即为SPP结构
5 ASPP
ASPP(atrous convolution SPP),其实就是跟SPP差不多,只不过引入了不同倍率的空洞卷积
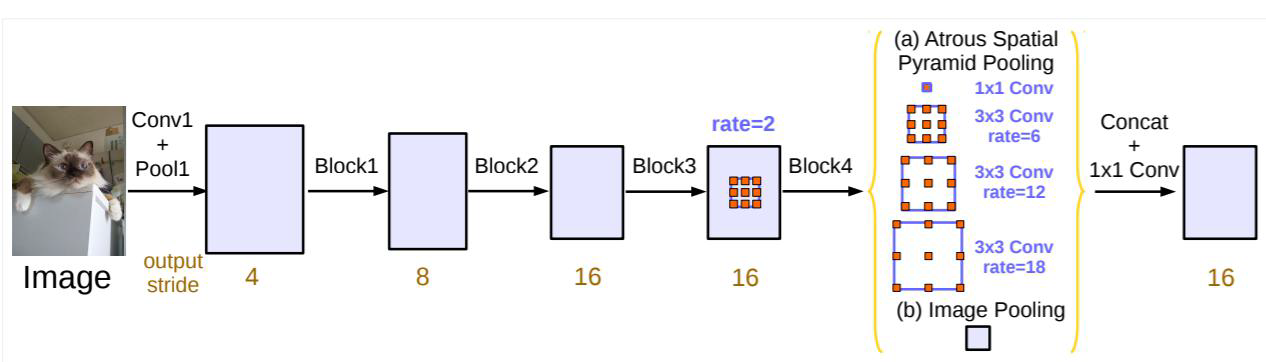
6、deepLabV3+
整体网络架构:
效果提升不算多
Backbone可以改进
创新不多所以不是4版
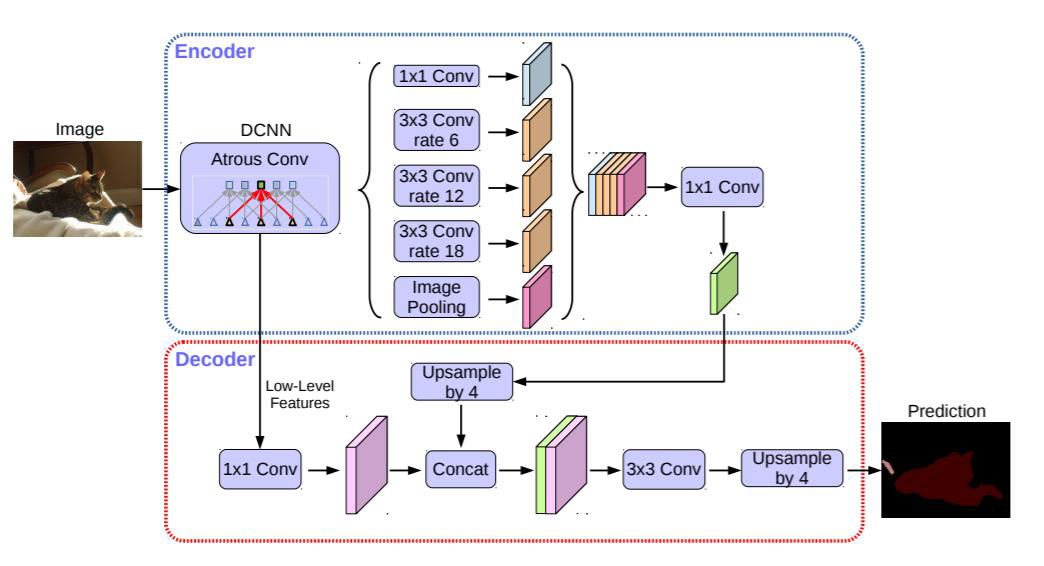
如图所示,在Encoder部分,先经过带有空洞卷积层的DCNN,再经过有4个不同尺度并行的空洞卷积,最后结构拼接后再经过一维卷积得到一个特征图,这就是Encoder的输出。
而Decoder的输入就是就是DCNN的浅层输出,也就是不是最后一层的输出。得到的是浅层特征,与Encoder的输出都经过一维卷积,再拼接在一起,而为了匹配特征图长宽大小,Encoder还会进行上采样操作。
拼接的特征再经过卷积和上采样,得到最后的输出。
这就是deeplab的基本概述和整体思想。