本节主要介绍PointNet语义分割,其中主干网络和代码环境等PointNet详细介绍请参考三维目标检测 — PointNet详解(一)_Coding的叶子的博客-CSDN博客,这里不再进行重复介绍。 PointNet文章作者关于三维物体检测的讲解请参考3D物体检测的发展与未来 - 深蓝学院 - 专注人工智能与自动驾驶的学习平台。
1 代码环境部署
请参考三维目标检测 — PointNet详解(一)_Coding的叶子的博客-CSDN博客。
2 数据介绍
2.1 原始数据
S3DIS(Stanford Large-Scale 3D Indoor Spaces Dataset )数据集是斯坦福大学开发的室内点云数据集,含有像素级语义标注信息。官方下载地址为http://buildingparser.stanford.edu/dataset.html,需要简单填一下信息,填完即可出现下载链接,不需要进行邮箱验证确认。
这里下载的数据集为Stanford3dDataset_v1.2_Aligned_Version.zip,解压之后有Area_1(44个场景)、Area_2(40个场景)、Area_3(23个场景)、Area_4(49个场景)、Area_5(68个场景)、Area_6(48个场景)六个文件夹,即6个不同区域。S3DIS在6个区域的271个房间中共采集了272个场景。每个场景包含一个txt点云文件和一个Annotations文件夹。这个txt文件是该场景的全部点云,每个点云含xyzrgb六个维度数据。Annotations文件夹下为各个类别的txt点云文件,同样存储了xyzrgb六个维度的数据。显然。各个类别的点云应该是总的场景点云的一部分。场景和语义类别共分为:
11种场景:Office(办公室)、conference room(会议室)、hallway(走廊)、auditorium(礼堂)、(open space开放空间)、 lobby(大堂)、lounge(休息室)、pantry(储藏室)、(复印室)、copy room(储藏室)和storage and WC(卫生间)。
13个语义元素: ceiling(天花板)、floor(地板)、wall(墙壁)、beam(梁)、column(柱)、window(窗)、door(门)、table(桌子)、chair(椅子)、sofa(沙发)、bookcase(书柜)、board(板)、clutter (其他)。
2.2 数据预处理
数据预处理脚本如下:
cd data_utils
python collect_indoor3d_data.py/data_utils/meta/anno_paths.txt存储了全部272个场景下的Annotations文件夹路径。/data_utils/meta/class_names.txt列举了上面13个语义元素的标签名称。将Annotations文件夹下的每个txt文件与语义标签类别进行合并,这样每一个点的数据组成为xyzrgbl,l表示标签序号labelid。将合并的文件再次合并到一起,例如Area_1/Conference_room_1/Annotations/文件夹下的33个文件内容加上标签后全部合并到一起,得到Nx7维度的点云数据,N表示该场景中的点云数量。
每个Annotations合并后的文件以numpy形式保存到data/stanford_indoor3d文件夹下,名称为区域_场景.npy,共271个文件,这说明其中1个场景未采集数据。这里并不去细究是哪一个场景没有数据。
2.3 模型输入数据
样本选取:区域Area_5中数据用作评估测试,其他区域数据用于训练。预处理会对每个房间采样4096个点,并且采样后所有样本的点的总数量与原始271个场景房间中点的总数量相等。在总数量保持不变的情况下,采样点的数量下降导致需要增加样本数量,因而同一个场景会多次采样,并且同个场景被采样的概率大小其点云占总数量的比例成正比。经过采样后,训练样本数量为47623,测试样本数量为18923。
4096个点的采样过程:随机选择点云中的一个点作为样本中心点,选取该点xy方圆1米内的点,z方向上不做限制。算法中限制这一步必须至少采样到1024个点。接着对采样出来的点随机选择4096个点,如果前一步点的数量大于等于4096则无重复选择,否则可重复选择出4096个点。
归一化:
(1)将采样出来的4096个点坐标减去上述采样的样本中心点坐标,得到Point[:3],并且输入模型前会进行旋转增强。
(2)将rgb颜色信息除以255,得到Point[3:6]。
(3)将采样出来的4096个点坐标除以房间中坐标的最大值,得到Point[6:9]。
最终模型的输入为的归一化点信息(4096x9)和类别标签(4096)。
3 模型结构
PointNet结构如下图所示,图中上半部分为分类网络并已经在三维目标检测 — PointNet详解(一)_Coding的叶子的博客-CSDN博客详细介绍。下半部分为分割网络,也是本节重点介绍的内容。
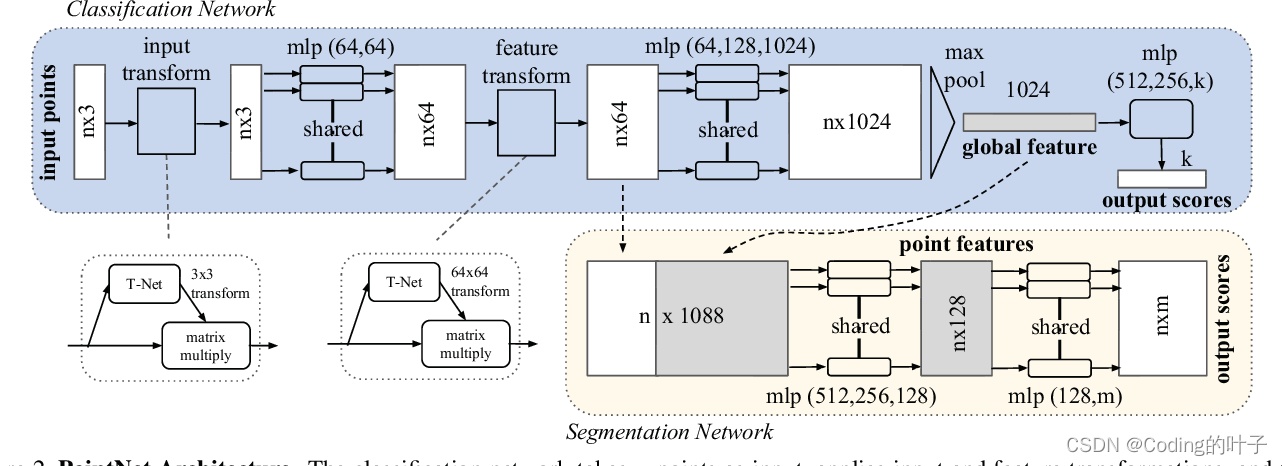
(1)分类部分的模型基本不变,部分变化包括:1)输入点的数量由1024变为4096。2)获取空间坐标变化矩阵的第一个卷积输入通道数量由3变为9。3)空间变换矩阵仅与输入点前3个坐标相乘,后6个维度不变;变换完成后经过卷积conv1d(9, 64)得到64x4096维特征。4)得到的1024维特征属于全局特征,重复拼接到上一步的特征得到1088x4096维度特征。
(2)中输出特征经过卷积conv1d(1088, 512)、conv1d(512, 256)、conv1d(256, 128)、conv1d(128, 13)、log_softmaxt得到13维度的输出,即13个类别log softmax(4096x13),即图中下方的output scores。
4 损失函数
损失函数由两部分组成,一部分是交叉熵损失函数,另一部分是64维特征的变换矩阵的损失。这里考虑到类别的均衡性,交叉熵损失函数会为每个类别分配一个权重。在全部原始点云中,同一类别的空间点数量最多的权重最小,取值为1。其他,类别的权重是最大点数量与该类别数量的比值的三分之一次方,显然其他类别的权重大于1。
矩阵变换相当于是在空间内坐标系的变换。因此,训练出的变换矩阵最好是正交矩阵,这样每个维度的特征尽可能保持相对独立。因此,第二部分的损失是矩阵相对于正交矩阵的差值,然后乘以损失系数0.001。
5 训练评估程序
首先运行2.2中的数据预处理脚本,data文件夹需要新建,默认是没有的。然后直接运行train_semseg.py和test_semseg.py即可完成训练和测试,默认的配置就是基础的PointNet。
python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_3d点云 python从三维基础知识到深度学习,将按照以下目录持续进行更新。https://blog.csdn.net/suiyingy/article/details/124017716更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。
